Many times, while surfing on the internet, we come across various websites which we are so informative that we want to save the website as a whole or the part of it to our local computer system. This can be used offline afterward so that the content becomes accessible even if there is a problem with the working of the internet connection. There are many tools that can deal effectively with this job, and the one very effective is Httrack. It is for free and has a host of features that are very impressive. But, you have to do a bit of homework as a lot of configurations have to be customized extensively before you get used to it. But, if you have no time for customizations, then you can use WebCopy. You will come to know that it is a very sophisticated program when you go exploring it deeply. The advanced configuration options can be simply ignored provided you just want to save the web pages to your computer system.
Download link for Httrack
Download link for WebCopy

The steps are very simple to follow:
Step 1: In WebCopy, there is a website field provided where you have to enter the website you want to save. You can either type the website address or copy and paste the URL.
Step 2: Select the folder to which it has to be saved.
Step 3: Finally, click on copy website to start the download.
This is all which needs to be done. The selected page starts getting processed by the program and you can view it in the results tab. All the files, which are getting downloaded, which are getting skipped and which are causing errors in the downloads are shown here. The error messages are very helpful in understanding why a particular error is disturbing the download. But, many times the user can never find a solution to this problem. There is a local folder button that can be accessed to see all the copies stored locally or these can be checked from the save folder also.
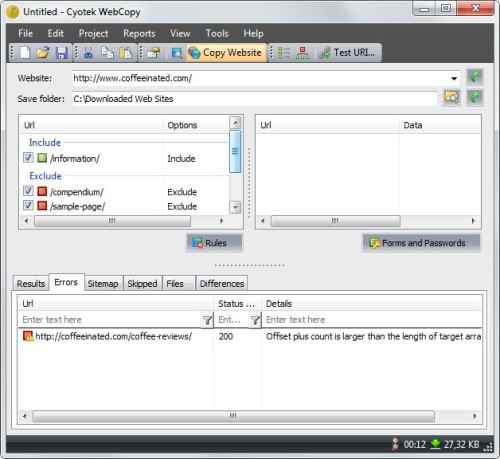
Till now, we have just discussed the basic options which can be used to copy a single web page. But, we need to define certain rules to download the additional pages and even the entire website. Defining rules also help to recognize the problems that the broken pages have faced and they can be skipped so that the remaining pages get downloaded very easily. This is very simple. There a listing rules on the main interface. Right-click on it which opens many options. Select add from here. The website structure is matched with the rules defined. For skipping any directory from getting crawled, simply select it and click on the Exclude option.
Note: The program requires the Microsoft .Net Framework 3.5. to run properly.
Useful tips:
- The active websites are displayed in the Website diagram menu, which can be used to add rules to the crawlers.
- Under Project Properties, additional URLs can be added which are to be included in the downloads. This particularly becomes very useful to the crawlers if they are not able to discover the URLs automatically.
- From the options menu, you can change the default user agent. This usually comes into the act when they are blocked by some servers and needs modifications for the websites to get downloaded.
Thus, downloading single pages is very easy, you need to work a bit in getting accustomed to the downloading multiple pages. But, you will excel with experience and this is very handy.